背景
随着公司某项业务的快速发展,相关表的数据量激增。为了应对这一增长,我们需要将这些表的数据迁移到新的数据库,并实现平滑切换。本文将探讨几种可能的迁移策略,并分析每种方案的优缺点。
测试环境搭建
为了模拟和测试各种迁移策略,我们首先使用 Docker 搭建了一个本地测试环境,包含三个 PostgreSQL 实例:
- pgsql:源数据库
- pgsql1:目标数据库
- pgsql2:用于其他操作
services:
pgsql:
image: postgres:13
ports:
- 5433:5432
environment:
POSTGRES_PASSWORD: 123456
pgsql1:
image: postgres:13
ports:
- 5434:5432
environment:
POSTGRES_PASSWORD: 123456
pgsql2:
image: postgres:13
ports:
- 5435:5432
environment:
POSTGRES_PASSWORD: 123456
迁移策略
一、主从复制
主从复制是一种直观的数据迁移方法,可以确保数据的实时同步。
配置步骤:
- 修改主库(源数据库)配置:
vim /var/lib/postgresql/data/pg_hba.conf
# 添加从库IP的访问权限
host replication all 172.20.0.3/32 md5
- 重新加载主库配置:
SELECT pg_reload_conf();
- 配置从库(目标数据库):
touch /var/lib/postgresql/data/standby.signal
vim /var/lib/postgresql/data/postgresql.conf
# 添加主库连接信息
primary_conninfo = 'host=pgsql port=5432 user=postgres password=123456'
- 备份主库数据到从库:
pg_basebackup -h pgsql -U postgres -p 5432 -F p -X s -v -P -R -D /var/lib/postgresql/data
- 重启从库
优点: 实现全量数据同步,操作相对简单。
缺点: 需要复制整个数据库,不适用于数据量巨大的情况。
二、逻辑复制
逻辑复制允许选择性地复制特定表或数据库对象,更加灵活。
配置步骤:
- 修改两个数据库的配置并重启:
vim /var/lib/postgresql/data/pg_hba.conf
# 修改 wal_level,重启才能生效
wal_level = logical
- 在主库创建数据发布:
-- 查看 wal_level 是否正确
show wal_level;
CREATE PUBLICATION my_publication FOR TABLE table_1, table_2;
-- 检查发布
SELECT * FROM pg_publication;
SELECT * FROM pg_publication_tables;
- 在从库订阅主库发布:
CREATE SUBSCRIPTION my_subscription
CONNECTION 'host=pgsql port=5432 dbname=postgres user=postgres password=123456'
PUBLICATION my_publication;
-- 检查订阅
SELECT * FROM pg_subscription;
优点:
- 可以选择性复制特定表,减少数据传输量
- 支持实时同步
缺点:
- 需要修改数据库配置并重启,可能影响其他业务
- 对于大量数据的初始同步可能需要较长时间
- 需要特别注意表结构变更和从库数据修改的问题
重要注意事项:
- 从库数据修改风险:
- 逻辑复制的从库并不是只读的。然而,直接修改从库数据可能会导致同步中断或数据不一致。
- 强烈建议不要对从库进行任何直接的数据修改操作。所有的数据变更都应该在主库进行,然后通过复制同步到从库。
- 表结构变更同步:
- 主库的表结构变更不会自动同步到从库。这是逻辑复制的一个重要限制。
- 如果需要变更表结构,必须在主库和从库上同时进行相应的修改。
- 确保从库中的表结构至少包含主库表的所有字段。如果从库缺少主库中存在的字段,同步将会失败。
- 序列(Sequence)处理:
- 表的序列不会自动复制。如果目标表需要使用与源表相同的序列值,需要手动设置。
- 配置修改影响:
- 修改
wal_level为logical需要重启数据库,这可能会影响到其他依赖该数据库的业务。 - 在生产环境中,重启数据库通常需要经过严格的变更控制流程,并选择在业务低峰期进行。
- 修改
三、停机维护
这种方法需要短暂停止服务,但可以确保数据一致性。
使用 pg_dump & pg_restore
使用 PostgreSQL 自带的工具来迁移数据。接下来的操作在 pgsql2 中执行。
pg_dump 是一种用于备份 PostgreSQL 数据库的工具。pg_dump 不会阻止其他用户访问数据库(读取或写入)。
pg_restore - 从 pg_dump 创建的归档文件中还原 PostgreSQL 数据库。
- 测试是否可以连接源数据库和目标数据库:
# 源数据库
psql -h pgsql -p 5432 -d postgres -U postgres
# 目标数据库
psql -h pgsql1 -p 5432 -d postgres -U postgres
- 备份源数据库:
pg_dump -h pgsql -p 5432 -d postgres -U postgres -Fd -j 5 -t table_1 -t table_2 -f dumpdir
- 恢复到目标数据库:
pg_restore -h pgsql1 -p 5432 -d postgres -U postgres -j 5 -c --if-exists -Fd dumpdir
使用 pgcopydb
pgcopydb 是一个用于 PostgreSQL 数据库复制和迁移的开源工具,可以利用并行处理来加速复制过程。
- 安装:
apt-get install pgcopydb
- 设置环境变量:
export PGCOPYDB_SOURCE_PGURI="postgres://postgres:123456@pgsql:5432/postgres"
export PGCOPYDB_TARGET_PGURI="postgres://postgres:123456@pgsql1:5432/postgres"
- 测试是否可以连接源数据库和目标数据库:
pgcopydb ping
- 创建过滤配置:
vim filter.ini
# 写入以下配置
[include-only-table]
public.table_1
public.table_2
- 执行迁移:
pgcopydb clone --drop-if-exists --no-comments --filters filter.ini --dir pgcopydb
耗时
分别使用两种方法迁移数据,查看耗时时间。
pg_dump & pg_restore

备份花费时间:23m23s
恢复备份花费时间:24m15s
备份文件大小:7.7G
pgcopydb
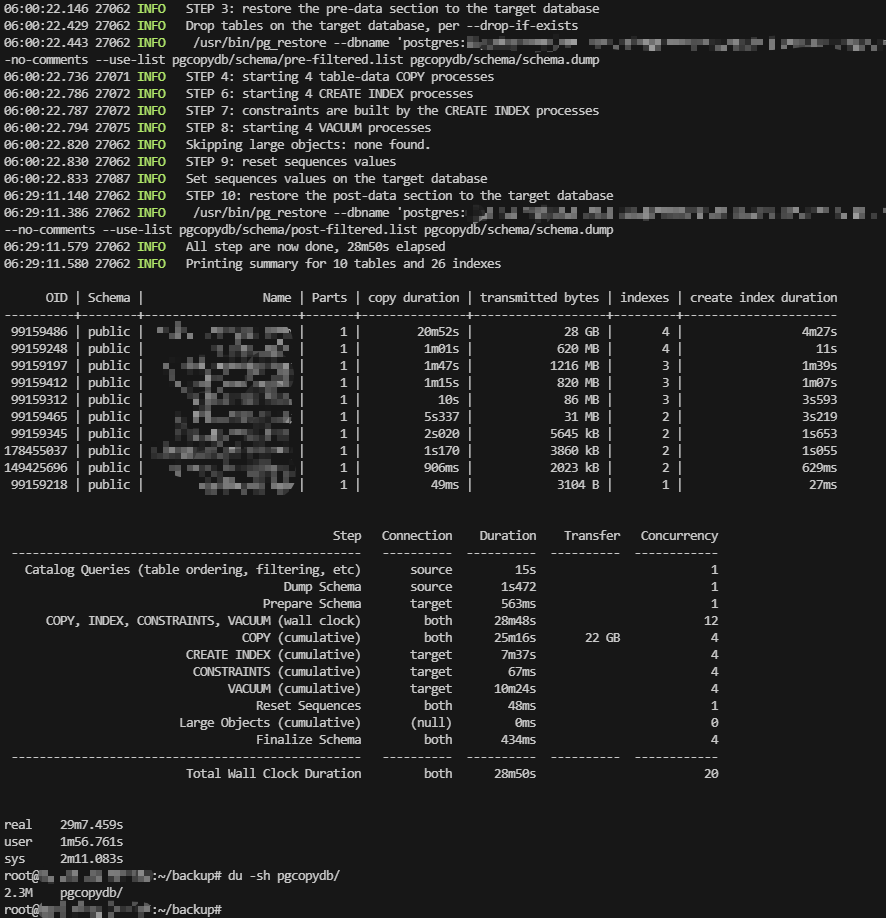
花费时间:29m7s
占用文件大小:2.3M
优点: 可以确保数据一致性,适用于可接受短时间停机的场景。
缺点: 需要停机维护,可能影响用户体验。
四、代码同步
通过代码实现实时数据同步,最小化对现有系统的影响。
实现步骤:
- 在源数据库创建变动记录表:
create table sync_log
(
id bigserial
primary key,
table_name varchar,
operation varchar,
data jsonb,
created_at timestamp default CURRENT_TIMESTAMP
);
- 创建触发器函数:
create function log_table_changes() returns trigger
language plpgsql
as
$$
BEGIN
IF (TG_OP = 'DELETE') THEN
-- 处理删除操作,记录 OLD 数据
INSERT INTO sync_log (table_name, operation, data)
VALUES (TG_TABLE_NAME, TG_OP, row_to_json(OLD));
RETURN OLD;
ELSE
-- 处理插入或更新操作,记录 NEW 数据
INSERT INTO sync_log (table_name, operation, data)
VALUES (TG_TABLE_NAME, TG_OP, row_to_json(NEW));
RETURN NEW;
END IF;
END;
$$;
- 对指定表创建触发器:
CREATE TRIGGER sync_table_1
AFTER INSERT OR UPDATE OR DELETE ON table_1
FOR EACH ROW EXECUTE FUNCTION log_table_changes();
- 在目标数据库创建进度表:
create table progress
(
id integer not null
primary key,
progress bigint
);
insert into progress
values (1, 0);
- 初始数据同步和实时同步:
- 首先,使用方案三(停机维护)的方法进行一次完整的数据库备份和恢复,确保目标数据库与源数据库的初始状态一致。
- 然后,使用自主开发的脚本 pg-sync-tables 实现实时同步。这个脚本是本方案的核心组件,专门设计用于处理 PostgreSQL 表的实时同步需求。
优点: 无需停机,实现实时同步,对现有系统影响最小。
缺点: 实现相对复杂,需要额外的开发工作。
结论
每种迁移策略都有其适用场景和权衡。根据业务需求、数据量大小和可接受的停机时间,选择最合适的方案至关重要。在本案例中,考虑到业务的特殊需求和数据量,最终选择了代码同步的方案,实现了最小化影响下的数据迁移。